Research Projects
-
 Image/Video Description with Natural Language
Image/Video Description with Natural Language

Generating natural language descriptions of visual content is an intriguing task. It has a wide range of applications such as text summarization for video preview, assisting blind people, or improving search quality for online videos. Our works focus on the following four main challenges for video captioning: 1) Multi-modalities, 2) Temporal movements, 3) Diverse topics 4)Wisdom of all
Best Performer on Video Caption task at TRECVID 2018
Best Performer on Video Caption task at TRECVID 2017
Best Performer at MSR Video to Language Challenge 2017
Best Grand Challenge Paper Award at ACM Multimedia 2017
Best Performer at MSR Video to Language Challenge 2016
Source Code -
Deep Intermodal Video Analysis

DIVA addresses activity detection for both forensic applications and for real-time alerting. It aims to develop robust automated activity detection for a multi-camera streaming video environment. As an essential aspect of DIVA, activities will be enriched by person and object detection, as well as recognition at multiple levels of granularity.
Best performer at activity detection challenge 2019 in surveillance videos hosted by NIST & IARPA.
2nd place at Surveillance Event Detection (SED) in TRECVID 2017
Source Code (event classifer)
Source Code (SED2017)
Technical Report -
Event Reconstruction
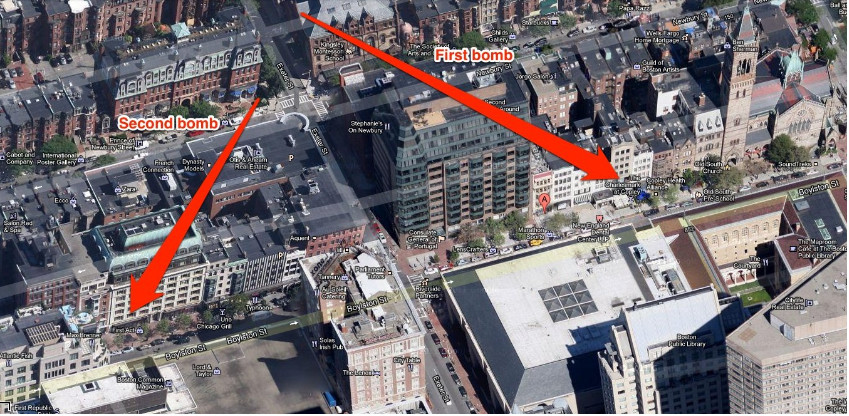
When an event happens, different videos capture different moments of the same event at different positions from different perspectives. The situation is very similar to the story of the "blind men and an elephant". The event truth corresponds to the elephant in the story, and each single video corresponds to one of the blind men who only touches parts of the elephant, either in the time dimension or in the space dimension. The goal of event reconstruction is to recover the elephant in its entirety from each of the blind mens' descriptions.